Can confirm, my main account and half my subscribed communities are down. Possibly unrelated, but my All is also screwy even though I’m on lemm.ee.
For all the annoyance, a silver lining is that lemmy.world is testing lemmy at a relatively high scale lemmy doesn’t see anywhere else and so aiding in the development of the software and architectural guidelines for instance management.
Yes. These are growing pains. That’s a good thing.
yep, another big outage.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
I moved to sopuli.xyz because of this. I can still subscribe to all the communities I like so no point in staying in an instance that’s constantly down.
Problem is, so many communities are on .world now, so it hurts even from another instance
I hope people on the Fediverse will finally learn not to choose the biggest instance all the time
I think it’s more like the previous commentor said. It’s the communities more than the users. Every post, comment, like needs to be sent to every other instance that subscribes to the community. I suspect it’s definitely connected to federation. The reason being, at 20:00 utc yesterday lemmy.world stopped sending my instance anything (previously it was between 2 and 5 messages a second). It only started again at around 00:00 utc. I wonder if they were slowly adding instances back to federation?
In any case the load for that many communities with that many other instances must be huge. The advantages of the fediverse requires that communities AND users are spread between instances. In the current climate, the super instances have most of both and it must be becoming exponentially harder to keep up with hardware requirements for this.
That’s a very valid point. Sometimes I question if very small instances (1-10 users) are not more detrimental than anything to the general performance
Whose fault is it though? If an instance is capable of 100 concurrent users but everyone flocks to the two or three big instances. What to do? Block instances so they shutdown? Then when the shit really hits the fan there’s nowhere to distribute users to.
In the case of lemmy.world I might suggest they split the instance. Original lemmy.world keeps the communities but has no users. Create a new instance and transfer the users. That way the first instance is dedicated to federating the communities, moving the real time user database hits to a separate database. I’d also suggest preventing the creation of new communities on that instance.
In real terms it’d have been better if the communities were shared between instances more. Making a more even spread of the one to many distribution efforts.
sounds like a cool idea. hit Ruud up once they’re less busy.
Dude just move to a small, updated instance with good uptime. I joined aussie.zone and its never down plus feels so much snappier.
i tried this, is it normal to never receive the verification email? it says verification sent, i tried 4 diff smaller instances, and its been like 10 hours. i checked the spam too
🤣🤣 its just you dude. I have switched instances multiple times and never had an issue like you described. Try aussie.zone instance
i am not australian but why not lol
edit: meh nvm, dont wanna wait to be accepted. im american anyway,
Doesn’t matter. Even I am not Australian but I am using aussie.zone
I’m not Australian.
Right Now
Working, this comment time
That’s why I use lemm.ee
That’s why I use lemm.ee
1993: God, how we would love it if someone could tell us anything was “just that simple”, and then of course when you see a pie chart you go “Oh, a pie chart…”. I mean, it has more religious meaning now than a crucifix to see a pie chart. I mean, because…. why is that so popular? Because it reduces complexity. The complexity is very real but his little soundbites - 1993
@garpunkal@lemm.ee - do you know of the history of site_aggregates PostgreSQL table?
no tell me more?
lemmy.ca staff was so frustrated with performance problems a couple weekends ago they cloned a copy of their database Running AUTO_EXPLAIN revealed site_aggregates logic in Lemmy was doing comment = comment + 1 counting against 1500 rows, for every known Lemmy instance in the database, instead of just writing 1 row.
huh?
huh?
Please explain in detail what “huh” means in this context.
As I said in the comment you replied to: do you know of the history of site_aggregates PostgreSQL table?
Not OP, but I feel like it was Huh? as in what the heck are you talking about and why was it a reply to thier comment
I have accounts on a few instances, and lemm.ee is the quickest and most stable of them all. I don’t know what they’re doing, but it’s great.
Removed by mod
lemdro.id also runs via horizontal scaling behind a load-balancer, soon to expand globally to keep response times down for people everywhere. We’re very resilient :)
I got accounts on lemm.ee, sh.itjust.works and kbin.social. I had one on .world in the beginning, but the performance wasn’t great. Probably too many users.
Probably too many users.
if local.lemmyusers > 15, crash constantly because of PostgreSQL nonsense logic and Rust ORM.
Name a more iconic duo, I’ll not wait
Ruggus (a former reddit alternative) and outages.
It was perhaps the single biggest unifying meme among it’s user base that their backend was an absolute dumpster fire ™
You can check lemmy.world’s status page to see when it’s down.
Problem is that many times it will say “partial outage” but the website doesnt even work so technically it’s a full outage. I assume it’s to keep the uptime % as high as they can. So that 98.XX% uptime isnt very accurate at all.
What is their motivation about lying about uptime? It isn’t a business with advertisers, it is some dudes hobby server and some people who are donating despite what the uptime percentage is
correct, I dont know if it’s automatic to partial outage and manual trigger to full or how that works in their backend. But almost every time I’ve seen a partial (orange) outage, it’s a full blown outage.
Now that I’ve found a workable userstyle that gives kbin the same information density as old reddit (Narwhal) it may be time to switch over here. For better or worse kbin’s funding situation seems a bit more ironclad. Also the fact that I can check Lemmy communities and do Mastodon at the same time is pretty attractive.
i prefer this one for reddit theme: kbin familiarity & og post here. also welcome to kbin <3
Latest:
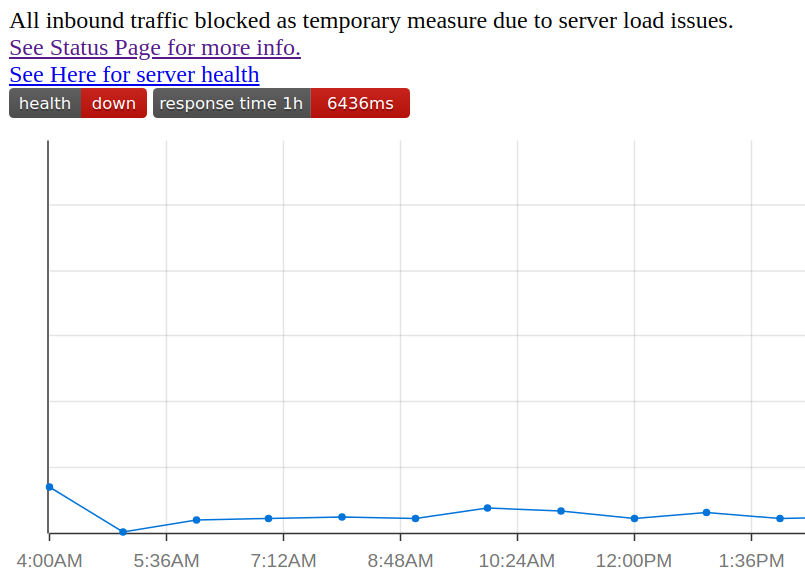

5801ms, terrible
This is what happens when people don’t understand federation.
Yep. Sitting on Lemmy.today browsing Lemmy.world posts right now…so I don’t know. Really advice people to not have just one account. :)
Do you know of the site_aggregates federation TRIGGER issue lemmy.ca exposed?
No. Care to explain please?
No. Care to explain please?
On Saturday July 22, 2023… the SysOp of Lemmy.ca got so frustrated with constant overload crashes they cloned their PostgreSQL database and ran AUTO_EXPLAIN on it. They found 1675 rows being written to disk (missive I/O, PostgreSQL WAL activity) for every single UPDATE SQL to a comment/post. They shared details on Github and the PostgreSQL TRIGGER that Lemmy 0.18.2 and earlier had was scrutinized.
I don’t know that it’s a DB design flaw if we’re talking about federation messages to other instances inboxes (which created rows of that magnitude for updates does sound like federation messages outbound to me). Those need to be added somewhere. On kbin, if installed using the instructions as-is, we’re using rabbitmq (but there is an option to write to db). But failures do end up hitting sql still and rabbit is still storing this on the drive. So unless you have a dedicated separate rabbitmq server it makes little difference in terms of hits to storage.
It’s hard to avoid storing them somewhere, you need to be able to know when they’ve been sent or if there are temporary errors store them until they can be sent. There needs to be a way to recover from a crash/reboot/restart of services and handle other instances being offline for a short time.
EDIT: Just read the issue (it’s linked a few comments down) it actually looks like a weird pgsql reaction to a trigger. Not based on the number of connected instances like I thought.
(which created rows of that magnitude for updates does sound like federation messages outbound to me)
rows=1675 from lemmy.ca here: https://github.com/LemmyNet/lemmy/issues/3165#issuecomment-1646673946
It was not about outbound federation messages. It was about counting the number of comments and posts for the sidebar on the right of lemmy-ui to show statistics about the content. site_aggregates is about counting.
Yep I read through it in the end. Looks like they were applying changes to all rows in a table instead of just one on a trigger. The first part of my comment was based on reading comments here. I’d not seen the link to the issue at that stage. Hence the edit I made.
You’ve become fixated on this issue but if you look at the original bug, phiresky says it’s fixed in 0.18.3
The issue isn’t who fixed it it, the issue is the lack of testing to find these bugs. It was there for years before anyone noticed it was hammering PostgreSQL on every new comment and post to update data that the code never read back.
There have been multiple data overrun situations, wasting server resources.
But now Lemmy has you and Phiresky looking over the database and optimizing things so things like this should be found a lot quicker. I think you probably underestimate your value and the gratitude people feel for your insight and input.
In layman’s terms please?
Every time you perform an action like commenting, you expect it to maybe update a few things. The post will increase the number of comments so it updates that, your comment is added to the list so those links are created, your comment is written to the database itself, etc. Each action has a cost, let’s say it costs a dollar every update. Then each comment would cost $3, $1 for each action.
What if instead of doing 3 things each time you posted a comment, it did 1300 things. And it did the same for everyone else posting a comment. Each comment now costs $1300. You would run out of cash pretty quickly unless you were a billionaire. Using computing power is like spending cash, and lemmy.world are not billionaires.
rows=1675 was the actual number on Saturday in July 2023.
rows=1675 from lemmy.ca here: https://github.com/LemmyNet/lemmy/issues/3165#issuecomment-1646673946
What if instead of doing 3 things each time you posted a comment, it did 1300 things. And it did the same for everyone else posting a comment.
Yes, that is what was happening in Lemmy before lemmy.ca called it out with AUTO_EXPLAIN PostgeSQL on Saturday, 8 days ago.
What are you asking for? lemmy.ml is the official developers server, and it crashes constantly, every 10 minutes it ERROR out, for 65 days in a row.
Latest, at the time of this comment: still over 4 SECONDS

Fresh as of comment time:

Are you just going to make one of these every single time?
Ugh
“Ugh” what?
Because it’s annoying.
deleted by creator
I’m indifferent about it.
I totally agree with your outlook and made a pretty similar post to yours a couple minutes ago. My only addition would be some concern as to why it seems like attacks are causing the downtime. The attacks do encourage improvement, but why do it in the first place. I’m hoping bored enthusiasts. At least it wouldn’t be BS corporate attacks trying to eliminate competition.