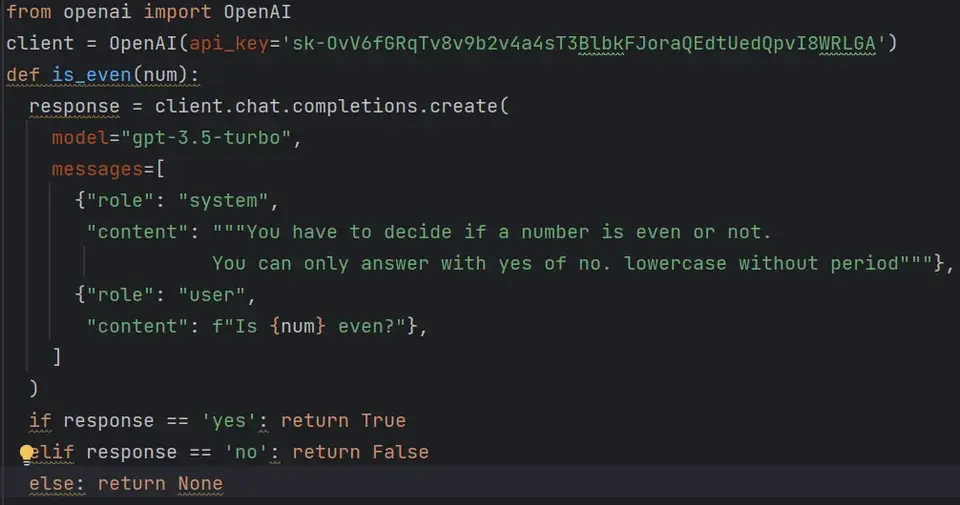
Don’t use OpenAI’s outdated tools. Also, don’t rely on prompt engineering to force the output to conform. Instead, use a local LLM and something like jsonformer or parserllm which can provably output well-formed/parseable text.
I’ll be informal to boost your intuition. You know how a parser can reject invalid inputs? Parsers can be generated from grammars, so we can think of the grammars themselves as rejecting invalid inputs too. When we use a grammar for generation, every generated output will be a valid input when parsed, because the grammar can’t build any invalid sentences (by definition!)
For example, suppose we want to generate a JSON object. The grammar for JSON objects starts with an opening curly brace “{”. This means that every parser which accepts JSON objects (and rejects everything else) must start by accepting “{”. So, our generator must start by emitting a “{” as well. Since our language-modeling generators work over probability distributions, this can be accomplished by setting the probability of every token which doesn’t start with “{” to zero.


{kind=link}
Don’t use OpenAI’s outdated tools. Also, don’t rely on prompt engineering to force the output to conform. Instead, use a local LLM and something like jsonformer or parserllm which can provably output well-formed/parseable text.
Agree this is better but neither of them actually seem “provable” though?
I’ll be informal to boost your intuition. You know how a parser can reject invalid inputs? Parsers can be generated from grammars, so we can think of the grammars themselves as rejecting invalid inputs too. When we use a grammar for generation, every generated output will be a valid input when parsed, because the grammar can’t build any invalid sentences (by definition!)
For example, suppose we want to generate a JSON object. The grammar for JSON objects starts with an opening curly brace “{”. This means that every parser which accepts JSON objects (and rejects everything else) must start by accepting “{”. So, our generator must start by emitting a “{” as well. Since our language-modeling generators work over probability distributions, this can be accomplished by setting the probability of every token which doesn’t start with “{” to zero.